Nueva publicación del lab: @ABMEjournal “Reproducibility and Repeatability of Five different technologies for bar velocity measurement”.
En este estudio se analiza en profundidad la calidad de la medida que pueden alcanzar algunos de los dispositivos más utilizados actualmente para la monitorización de la velocidad de desplazamiento de las cargas.
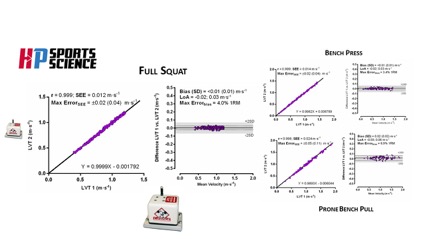
Todos los miembros del grupo HP Sports Science y sus colaboradores estamos muy satisfechos con los resultados de este trabajo publicado recientemente en la prestigiosa revista americana ABME, especializada en ingeniería biomédica (IF 3,41- Q1).
Este artículo se encuadra dentro de un proyecto más amplio que pretende analizar de forma exhaustiva las tecnologías disponibles en la actualidad para monitorizar la velocidad de desplazamiento de las cargas durante el entrenamiento de fuerza. Aunque ya de por sí los resultados son relevantes para los profesionales del entrenamiento, es quizás la metodología, el diseño y el análisis de datos los más destacable desde una perspectiva de investigación.
Lamentablemente, es muy habitual en nuestro campo de estudio encontrarnos trabajos que carecen de la calidad metodológica necesaria que permita a los investigadores alcanzar ciertas conclusiones practicas e interpretaciones no sesgadas.
Recomendamos sinceramente una lectura sosegada de todo el trabajo, especialmente la metodología y discusión. Aunque el texto en su conjunto, figuras y tablas, recogen en detalle todos los aspectos del proyecto, cualquier consulta podéis hacérnosla llegar a hpsportsscience@gmail.com
Prof. Jesús G. Pallarés – IP Human Performance & Sports Science – Universidad de Murcia
Texto explicativo sobre algunas posibles deficiencias de los trabajos en los que se pretende confirmar la “fiabilidad” y “validez” de un nuevo instrumento de medida.
Prof. Juan José González Badillo – Universidad Pablo de Olavide
Recientemente se vienen publicando muchos trabajos en los que se pretende confirmar la “fiabilidad” y “validez” de nuevos instrumentos de medida (medidores) de la velocidad de desplazamiento de cargas externas. Para contrastar la “fiabilidad y validez” del nuevo medidor se suele tomar como referencia otro medidor que, supuestamente, mide bien. Este planteamiento es razonable y adecuado, siempre que el medidor de referencia sea válido. Sin embargo, aparte del posible problema relacionado con el grado de “bondad” del medidor de referencia, suelen surgir otros al seleccionar y aplicar las pruebas destinadas a confirmar la “fiabilidad y validez” del nuevo medidor.
Hemos de tener en cuenta que cuando se hace un estudio de estas características, lo que se pretende comprobar es el grado de acuerdo de las medidas dadas por el nuevo medidor con las que da el medidor de referencia, ya validado previamente. También se debe considerar que para que “un instrumento”, “un medidor”, “un test”… sea válido debe confirmarse que mide con fiabilidad, pues no es suficiente “que mida lo que dice medir”. Todos los medidores “de velocidad” tienen validez aparente por definición, por diseño…, pues están hechos para medir velocidad, pero el instrumento puede resultar de muy baja o nula validez si no mide con suficiente precisión (error sistemático) o con suficiente estabilidad (error aleatorio).
El procedimiento más habitualmente utilizado, y a veces el único, para confirmar la “validez” del medidor consiste en comprobar si los valores de las medidas que ofrece el nuevo medidor presentan una alta relación con los ofrecidos por el medidor de referencia. Si se da una alta relación, se concluye que el nuevo medidor “es válido”, y que podría ser intercambiable o sustituir al medidor de referencia. Esta conclusión puede ser claramente errónea, porque para que esta correlación sea realmente un indicador de la “validez” del nuevo medidor, además de presentar un alto valor de correlación, la recta de regresión tendría que coincidir, prácticamente, con la bisectriz del ángulo formado por los dos ejes de coordenadas, lo cual exigiría que la recta pasara por el origen o valor cero de dichos ejes. Esto significa que el valor de “a” o término independiente de la ecuación de regresión: y = bx + a, debe ser muy próximo a cero, y el coeficiente “b” o pendiente de la recta de regresión muy próximo a 1. Si no se dan estos valores en la ecuación, por muy alta que sea la correlación, la validez del nuevo medidor puede ser nula, ya que incluso con un valor de r = 1, se estaría dando un error sistemático importante, mayor cuanto más se aleje “b” del valor 1 y más se aleje “a” del valor cero, tanto por defecto como por exceso.
En otros casos, aplicando este mismo procedimiento nos podríamos encontrar una recta de regresión que estuviera muy próxima a la bisectriz del ángulo de los ejes, pero con una correlación no muy elevada, por ejemplo, entre 0,8 y 0,9, lo que en muchos casos se considera como una “alta” y “suficiente” correlación para aceptar la “validez de algo”. Pero esto significa que incluso aproximándose al requisito de darse una pendiente muy próxima a la bisectriz y al paso de la recta por el origen de los ejes, el error aleatorio puede ser excesivo, por falta de asociación o correlación entre ambas medidas.
En cualquier caso, el grado de “validez” de estas correlaciones tiene que complementarse con un alto valor del coeficiente de correlación de concordancia de Lin (CCC_Lin), que es un indicador del grado de acuerdo entre los medidores y del error sistemático entre sus medidas. El CCC_Lin es directamente proporcional a la covarianza de ambas medidas e inversamente proporcional a la varianza de las medidas de cada medidor y a sus medias. Su valor máximo, que indicaría un acuerdo perfecto entre los medidores (entre sus medidas), es igual a 1, y solamente se consideran “valores sustanciales”, aunque no perfectos, los que son >0,95. Por tanto, por muy alta que fuera la correlación entre las medidas de los dos medidores, el no cumplimiento del ajuste a la bisectriz o un excesivo error aleatorio, o ambos, se correspondería con un CCC_Lin bajo, por lo que el nuevo medidor no podría considerarse “suficientemente válido” para medir.
Una información complementaria al ajuste de los puntos a la bisectriz es la desviación cuadrática media (DCM). La DCM es proporcional a la media de las distancias de cada punto a la bisectriz (el grado de ajuste). Por tanto, cuanto más se acerque este indicador al valor cero, mayor será el grado de acuerdo entre ambos medidores y menor tenderá a ser el error sistemático constante y proporcional y el error aleatorio.
El grado de acuerdo de las medidas también debe contrastarse a través del cálculo de los límites de acuerdo propuesto por Bland y Altman. Este procedimiento, aunque con menos frecuencia que la correlación, suele utilizarse en algunos estudios, pero, habitualmente, no se llega a hacer una suficiente y adecuada interpretación de los resultados. Este análisis se realiza a través de un gráfico, en cuyo eje X se encuentran las medias de cada par de puntuaciones de los medidores y en el eje Y las diferencias entre cada par de puntuaciones. Los límites de acuerdo se consideran aceptables si el 95% de las diferencias entre cada par de puntuaciones se encuentra dentro del intervalo de ±1,96 desviaciones típicas (dt). Este tipo de ajuste suele cumplirse con frecuencia, aunque esto no garantiza que el nuevo medidor presente un acuerdo suficiente con el medidor de referencia. En este sentido, Bland y Altman indican que es difícil determinar la bondad de los límites de acuerdo, pero sugieren que no sería aceptable una diferencia mayor que el doble de la media de las puntuaciones. Además de este requisito, el gráfico no debe mostrar una tendencia a aumentar o disminuir la dispersión de los datos (las diferencias entre las puntuaciones de los dos medidores) a medida que aumentan o disminuyen las medias, es decir, no debería haber relación entre la magnitud de las medias de las puntuaciones y la dispersión de las diferencias. Esto sería un indicador de error sistemático progresivo, en una dirección o en otra. Además, hay que considerar el valor de la media de las diferencias, que viene a indicar el error sistemático, por lo que cuanto más próximo a cero sea este valor, mejor. Así como la varianza de las diferencias, que indica la dispersión del error aleatorio o imprecisión de las medidas, por lo que este valor debería ser también muy próximo a cero.
Pero la principal valoración de los datos derivados de este procedimiento gráfico, y que nunca hemos encontrado en ningún estudio, es la determinación subjetiva, pero profesional y justificada, del rango aceptable de diferencias entre la puntuación superior y la inferior de los límites, obtenida al sumar y restar las dos deviaciones típicas (1,96 dt) a la media de las diferencias de las puntuaciones. Si estamos hablando de velocidad de ejecución, los límites aceptables deberían establecerse en función del grado de error en el que se incurriría al determinar el porcentaje de la RM que representa una carga absoluta (peso) dada al desplazarla a la máxima velocidad posible. Por ejemplo, si hemos medido la velocidad de desplazamiento de las cargas y nos encontramos que los valores límites de la media de las diferencias ±1,96 dt son 0,02 y -0,02 m·s-1, la mayor diferencia probable en el intervalo del 95% será de 0,04 m·s-1. Con estos datos, si se tratase de un ejercicio cuyas diferencias de velocidad entre valores diferentes entre sí en un 5% de la repetición máxima (RM) fueran de 0,08 m·s-1, el máximo error que se podría dar en los casos más extremos al determinar el porcentaje de 1RM que representa una carga absoluta dada sería del 2,5% (el 50% del 5%, que, como hemos indicado, exigiría una diferencia de 0,08 m·s-1), lo cual se puede considerar, en la práctica, como un resultado admisible y de suficiente precisión en la medida. Sin embargo, si los valores extremos fueran, por ejemplo, de 0,117 y -0,031 m·s-1, aparte de observarse un cierto error sistemático al estar desplazado el límite superior claramente por encima del cero y el inferior muy próximo al cero, nos encontramos que la diferencia máxima podría ser de ~0,15 m·s-1. Si consideramos el mismo ejercicio anterior, el máximo error que se podría dar en los casos más extremos al determinar el porcentaje de 1RM que representa una carga absoluta dada sería casi del 10% (el 10% exigiría una diferencia de 0,16 m·s-1), lo cual ya se puede considerar como un resultado demasiado distante del valor real de la carga relativa con la que se entrena. Y ya sería un medidor claramente deficiente si, por ejemplo, en un ejercicio en el que las diferencias de velocidad para cada 5% fuera de 0,06 m·s-1 y los valores extremos de los límites fueran 0,19 y -0,14 m·s-1, el error máximo se iría a más del 27% de diferencia entre la intensidad real (% de 1RM) a la que entrena el sujeto y la que nos indicaría el nuevo medidor. Y este importante error se puede dar, y de hecho se ha dado, incluso encontrándose el 95% de las puntuaciones (puntuaciones correspondientes a las diferencias entre los dos medidores en cada valor de medida) dentro del intervalo de confianza del 95% en el gráfico.
Un estudio complementario de este análisis sería el cálculo del error de estimación derivado de la correlación de las medidas de ambos medidores. Si aplicamos la correspondiente ecuación de regresión, el conocimiento de este error nos permitiría calcular un nuevo intervalo de confianza (del 95%) en el que se podría encontrar el valor ofrecido por el nuevo medidor ante un valor determinado del medidor de referencia. Naturalmente, cuanto más amplios fueran los límites de este intervalo, mayor sería el error probable que se podría cometer al aceptar el valor de velocidad indicado por el nuevo medidor. La cuantificación práctica de estos errores se haría de la misma manera que hemos indicado en el párrafo anterior. Además, una valoración de la validez del error indicado por el procedimiento del gráfico (Bland-Altman) y del error de estimación sería la coincidencia en la magnitud de los resultados de ambos procedimientos. De hecho, si los cálculos se hacen correctamente, se podrá observar que los límites extremos de error obtenidos por ambos procedimientos son prácticamente iguales.
Todos los análisis de acuerdo o concordancia entre medidores se deben hacer comparando los resultados registrados por cada medidor ante una misma realidad, es decir, ante una única medida de velocidad, en este caso. Para ello se deberían aplicar, al menos, todos los procedimientos que hemos descrito, pero aún sería conveniente y adecuado analizar si se dan o no diferencias entre las medidas registradas por cada medidor y si se da interacción entre las medidas y los instrumentos de medida (medidores). Para ello podríamos considerar las medidas ofrecidas por cada medidor como si fueran dos medidas de los mismos sujetos. Para este análisis aplicaríamos el cálculo del coeficiente de correlación intraclase (CCI) y el coeficiente de variación (CV). Teóricamente, las únicas diferencias o fuente de varianza que deberíamos encontrar serían las correspondientes a los sujetos o, más propiamente, a las diferencias de velocidad entre sujetos o entre diferentes medidas del mismo sujeto, lo que vendría estimado por el CCI, que en este caso sería igual a 1. Por tanto, si se dan diferencias entre ambos medidores ante una misma realidad medida (error sistemático), y si se da interacción medidas-medidores, lo que indicaría que estas diferencias no son constantes ni en la misma dirección ante cada valor de velocidad (error aleatorio), el nuevo medidor no presentará acuerdo con el de referencia, ya que el CCI sería bajo y el CV alto. Por tanto, podemos añadir tres indicadores más al análisis del acuerdo del nuevo medidor: los valores del CCI y el CV y las diferencias entre medidas. Además, es determinante indicar el procedimiento que se utilice para calcular el CCI, ya que si aplicamos un procedimiento que no tenga en cuenta las diferencias de medidas, el valor del CCI puede ser claramente superior que si estas son tenidas en cuenta. Por tanto, el procedimiento correcto es el que considera como término de error la media cuadrática intra, que engloba las diferencias entre medidas y la interacción medidas-sujetos o medidas-instrumentos, en este caso. De la misma manera, el CV debe derivarse de un error típico de medida determinado por la raíz cuadrada de la media cuadrática total. Por tanto, si no se indica el procedimiento utilizado en ambos casos, o incluso en uno de ellos, no se puede confiar en los resultados.
Además de todo lo anterior, podríamos hablar de una consecuencia que tendría en la práctica la utilización de un medidor deficiente para llevar a cabo un típico análisis de fiabilidad cuando se realizan dos mediciones de la misma variable al mismo grupo de sujetos. En este caso, registraríamos las dos mediciones con el medidor de referencia y con el nuevo. Los cálculos y las fuentes de varianza serían los mismos que los indicados en el párrafo anterior. Dado que los datos analizados por los dos medidores son los mismos, el valor de “la fiabilidad” de las medidas ofrecido por ambos tendría que ser idéntico o extremadamente próximo. Es decir, “los sujetos tendrían que ser igualmente fiables” con los dos medidores. Pero si el medidor nuevo no presenta acuerdo con el de referencia, nos podríamos encontrar con el hecho de que cada medidor nos diera unos valores de fiabilidad demasiado distintos. Esto nos llevaría a concluir, ante la misma realidad, “que los tests o los sujetos (propiamente las medidas) son fiables o que no lo son”, dependiendo del medidor utilizado. Naturalmente, si el medidor de referencia indica buenos valores de fiabilidad y el nuevo no, esto se deberá a la falta de acuerdo (invalidez) del nuevo medidor, pues a la variabilidad propia de los sujetos en los dos tests ‒única variabilidad detectable y real al utilizar el medidor de referencia‒, se le habrá añadido la variabilidad propia del nuevo medidor. Por tanto, ante la misma realidad medida, un medidor nuevo deficiente siempre dará unos valores de fiabilidad inferiores a los que dé el de referencia. Esto sería una consecuencia práctica grave de la falta de acuerdo o concordancia del nuevo medidor con el de referencia, porque con frecuencia estaríamos concluyendo que determinados tests o sujetos no son fiables cuando realmente lo son, o que los resultados de un test después de un entrenamiento son significativos o no, cuando realmente no podemos confiar en estos resultados. Este problema, probablemente, se ha dado y se está dando en la mayoría de los estudios.
Además de lo indicado, de este mismo análisis se puede obtener otra aplicación útil. Se trata del cálculo del mínimo cambio detectable (MCD) como indicador del grado de cambio (o diferencia) mínimo necesario para determinar si hay diferencias entre dos sujetos en la misma variable medida o en el mismo sujeto en dos momentos distintos. Este valor de deriva del error típico de las diferencias de medida, que multiplicado por 1,96 nos dará el límite máximo de diferencia a partir del cual los valores serían probablemente distintos. Pues bien, si un medidor mide bien, los valores del MCD se ajustarán a la realidad de la fiabilidad de las medidas, pero si mide mal, se dará un valor de MCD mayor. Esto significa que la posibilidad de detectar cambios probables de medidas es menor, es decir, el test (resultado del comportamiento de los sujetos más el del medidor) tendrá menos capacidad de discriminación o de resolución en las medidas entre sujetos y entre dos medidas de la misma variable en el mismo sujeto. Es decir, hará falta una mayor diferencia entre las medidas para considerarlas como diferentes.